David Souther - Arrow of Maturity - 2025-12-17
Programmers and software teams grow along what I have seen as a relatively common path of architectures. The steps are 0. Prototyping, 1. Straight-through handlers, 2. three phases of DDD (Domain Model, Extracted Repository, Discovered Unit of Work), and finally 3. Event-sourced Microservices. This view is admittedly tilted towards cloud architectures - distributed systems implementing business rules.
Prototyping & Data Engineering
An audacious amount of programming happens in the Data Engineering phase. By a 2018 account, 9 out of every 10 companies used spreadsheet models to make financial and business decisions [Accounting Today, archive]. MBA programs offer specific courses on using Excel. These are real programs that perform real computation to do real work around the globe. Most of these never grow beyond a one-off analysis; some live for years (decades?) behind the scenes of a back office; and a very select few become candidates for IT departments to create fully-fledged applications through a software development lifecycle.
Many users would deny that Spreadsheet usage is programming, and that’s OK. Their utility to companies and to the world economy remains undeniable, and their value will improve with better access to more data. Some of these users move from spreadsheets to raw SQL access to data connections, through tools like Amazon Redshift, Azure Synapse, or Google BigQuery. These types of tasks have proven highly amenable to LLM-assisted querying, as the LLM is best positioned to “translate” from “English to SQL”.
The key, defining feature for this stage is the lack of a software development lifecycle.
Straight-through Handlers
The first stage of Software Engineering takes a design or desire for a product, and implements a straight-through code path. Commonly called “N-Tier” architectures, a server is connected to an incoming Internet socket, typically configured to speak HTTP. Incoming requests are translated directly into database calls (possibly with an ORM library), and passed directly to the database. This type of program is liable to devolve into “big ball of mud” architecture without active effort, but it’s the most common approach to teaching and starting greenfield projects. See a range of “full stack” development books, including Learning PHP, MySQL, and Javascript, Full Stack React Projects, and Zero to Production: Rust.
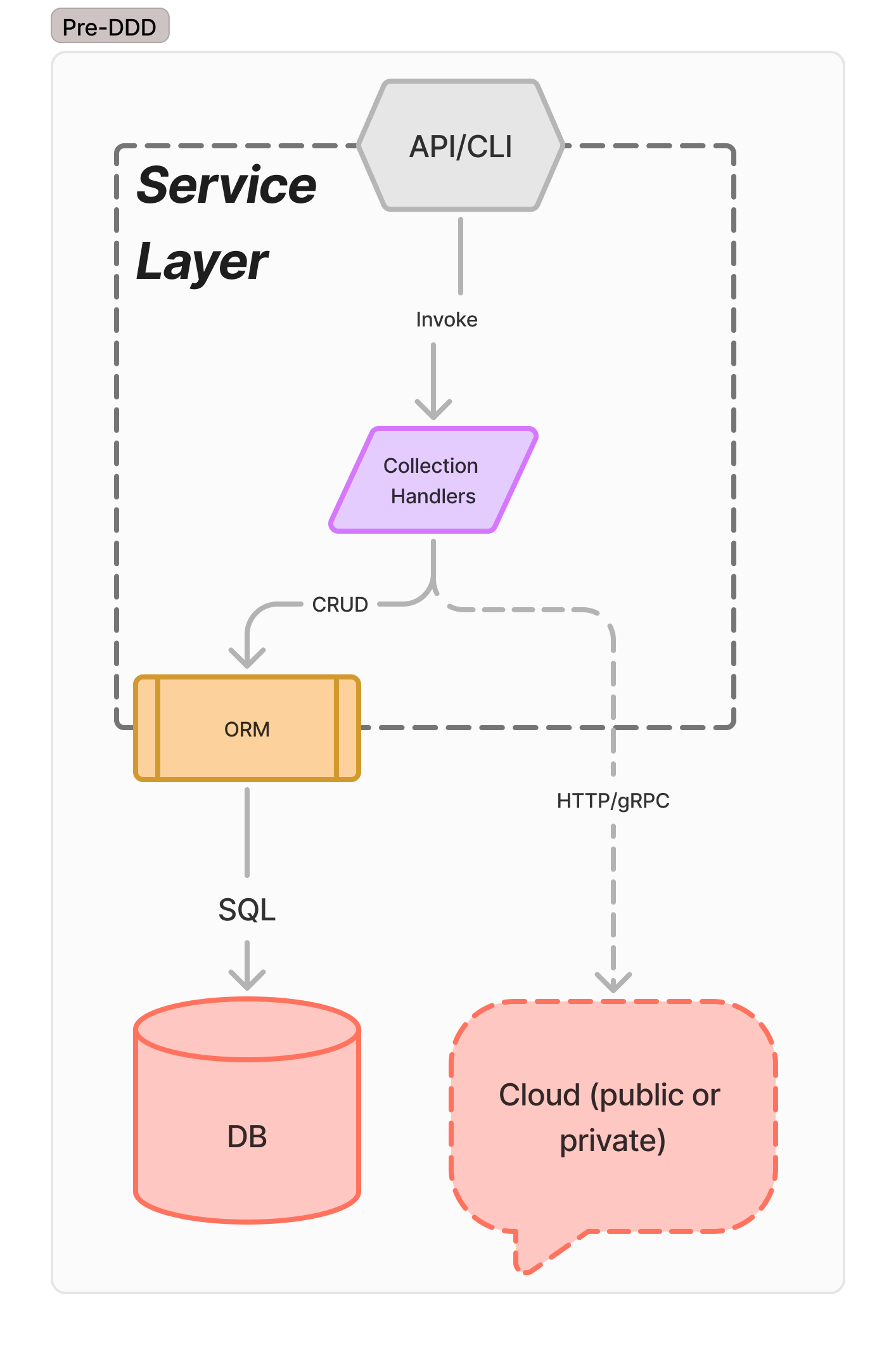
This is the starting state for many services in distributed systems, and, broadly, remains the architecture that Django and Rails default to. This can work for many teams for quite a long ways, but has no guardrails that defend against collapsing into a big ball of mud.
For pure-CRUD systems with no logic beyond API and ORM validation rules, there’s no reason to move beyond this view of the world, and can be provided by a Form-to-Table tool with only providing the ORM model.
This architecture is common in quick-to-market services, greenfield solo & small team developers, and many places where “software architecture” is considered a dirty phrase. (All buildings, and all software, has an architecture, even if it’s a big ball of mud.) Regardless of so-called code quality, at this stage the tool must follow an SDLC of some form, at the very least including a “develop” phase and a “deploy” phase. Testing may be handled by robust integration testing, but more often is sparse or non existent.
Three Phases of DDD
As teams and developers mature through the Straight-through Handlers phase, any focus on quality and architecture will naturally grow a domain model, arriving at some stage of Domain Driven Development (DDD). Some teams may do this as an explicit exercise; others will accidentally come to a domain model through accretion and reduction of language. Within the DDD stage, there are three broad phases of decoupling. Projects may evolve and refactor through them; teams with seasoned developers often jump to the end at their first day.
Domain Model
The first refactoring along the arrow of maturity is finding the domain model within the service. Domain models naturally exist by right of language; teams will, intentionally or not, find language that aligns along a domain model. It might not be the most consistent, the most focused, the most concise, but it will arise as the team uses language in their designs.
In this stage, the data model has isolated into DDD primitive data aspects, but data objects directly interact with their database (possibly via ORM). API calls domain service and Entity items directly.This is a necessary step to transition into DDD from CRUD, and to begin applying business logic rules to the handlers. This turns the API CRUD handlers into Domain Services, limiting the ways entities and values change to well-defined lifecycles.
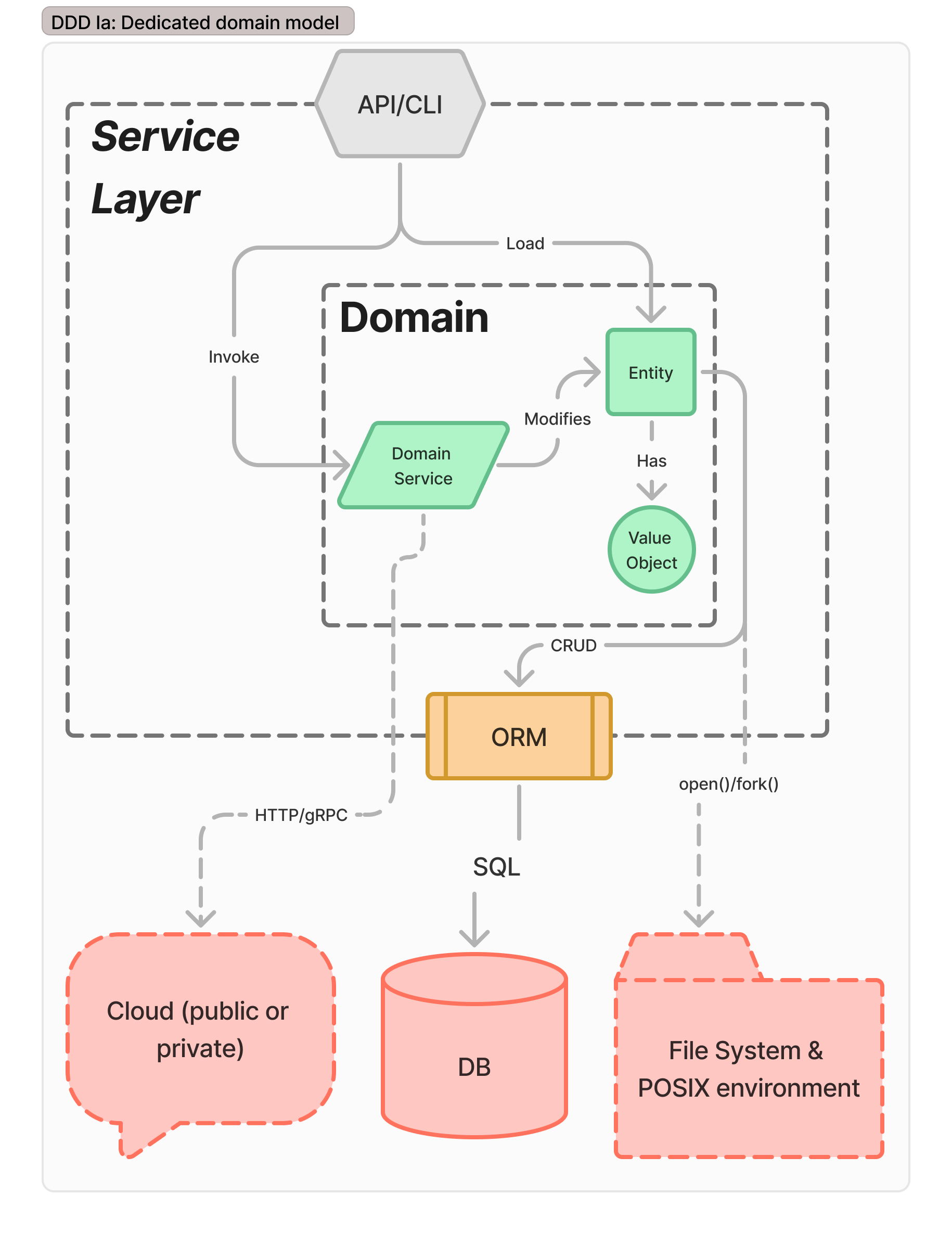
Because each domain service has a unique lifecycle defined by business rules, it becomes harder to find extractable library components. The ORM, if present, stays, or direct SQL if not using the ORM. Unfortunately, this has deep connections between entities, domain services, and the data persistence layer. This is not an appropriate stop on the road, and should only be a waypoint to Extracted Repositories
Extracted Repository
Tying Domain objects directly to storage mixes concerns, causing substantial developer pains. Tests necessarily mix abstraction layers. Mocks abound. Edge cases accumulate, and focus wanders. By extracting repositories, clear interfaces separate storage concerns from the domain model. Unit tests in the domain exercise only and exactly the business aggregates.
The domain model retains behavior from the Domain Model stage, but gains independence by extracting persistence into an abstract repository that serves as a facade for CRUD operations. This can then be replaced with a number of alternate data sources, include fake and dev DBs for testing.
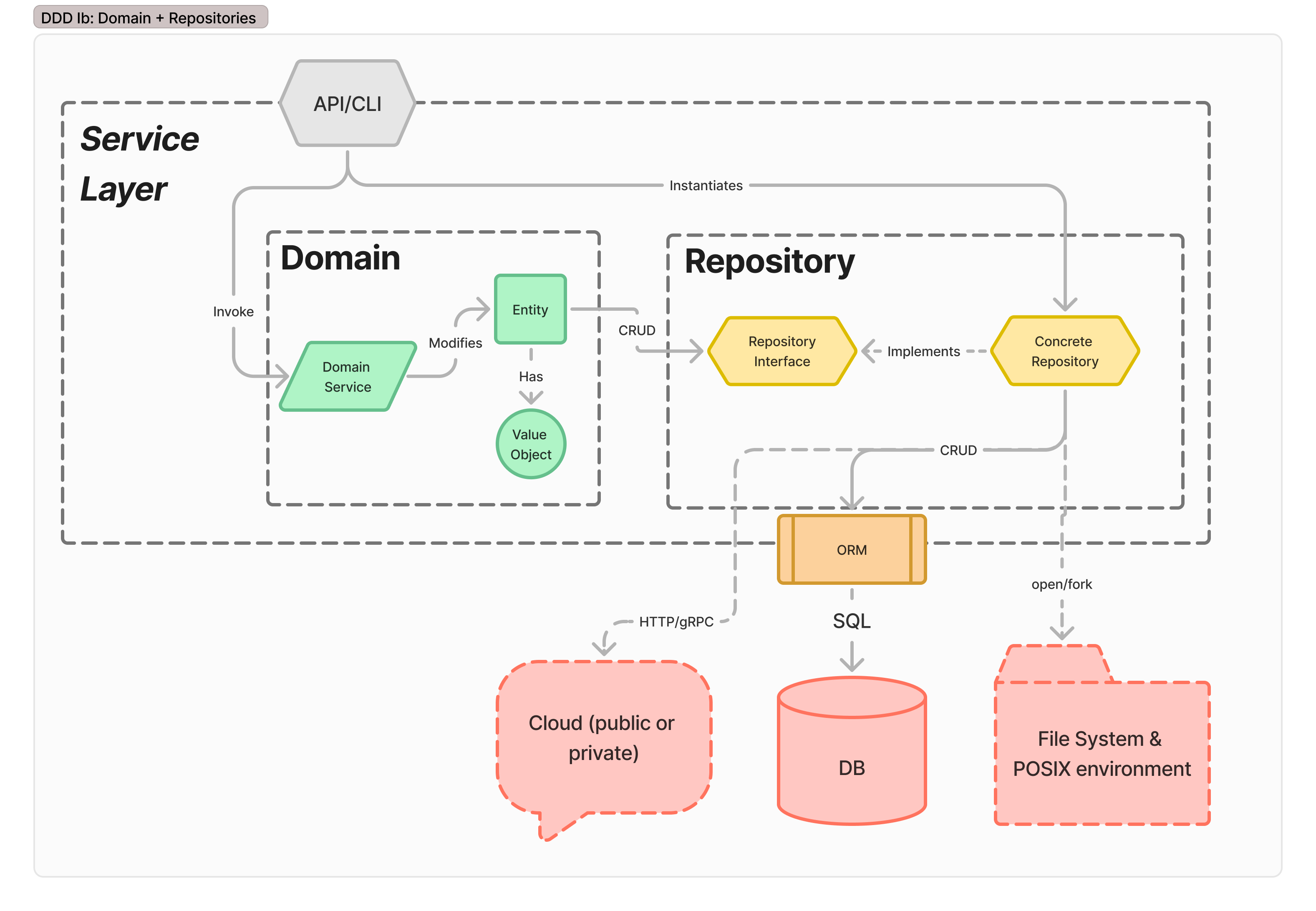
Services that transition to this level of maturity & architecture end up with three model definitions - an internal format for the domain model, the database schema, and the API schema. The API component takes responsibility for validating (and rejecting invalid) incoming requests. Assuming microservice ownership of the data store, the domain model can be confident persisted data is always correct. Simple errors can be returned through the API as 500 errors (or equivalent).
There are now three distinct definitions for any type in the system - the Domain Model type (which has necessary business invariants), the Storage type, which maps cleanly to the storage model (perhaps as a ORM instance for marshaling, or specifically using the downstream SDK’s type), and a pair of Request and Response types. Some teams will cut corners and tie the domain models directly into the API and Storage wrappers. This can be OK, if no further growth is needed or expected. Accepting that the service has ossified says substantially more about the project lifecycle coming to an end, and the product being “finished”. Many services probably should stop here and reconsider business objectives before moving to later stages on the arrow of maturity.
Aggregates & Units of Work
Domain services will grow to handling multiple Entities in a single operation. This leads to the first error boundary, and the need to handle transactional behavior. This earns complexity primarily driven by the lifecycle of the transaction itself.Managing multiple entities in a single operation leads to the DDD notion of an aggregate, “a cluster of domain objects that can be treated as a single unit.” Which is great in architecture, but not how the database sees things - changes to multiple tables requires a transaction.
To manage the transaction’s state, the architecture introduces a Unit of Work component. Additionally, the validation and verification logic is pulled out of the API and into a dedicated Handler. At this point, there may be three distinct definitions for any type in the system - the Domain Model type (which has necessary business invariants), the Storage type, which maps cleanly to the storage model (perhaps as a ORM instance for marshaling, or specifically using the downstream SDK’s type), and a pair of Request and Response types.
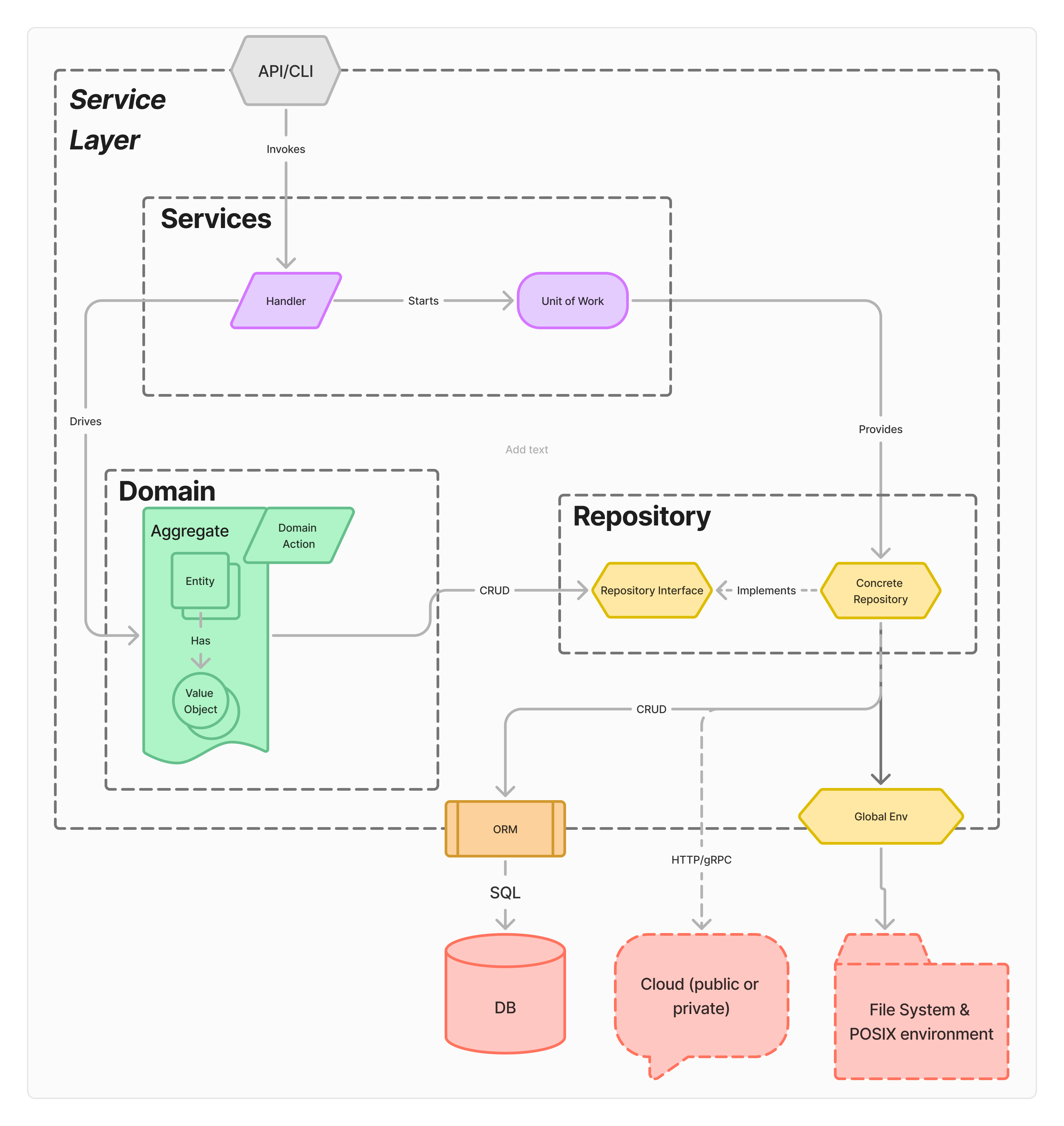
This layer retains the three different definitions of model types, but the API layer will need an update. Rather than directly mirroring & often duplicating the domain types (especially common in resource-oriented APIs), the API’s request and response type focus on the necessary data for the Aggregate operation. While this may necessarily include much of the data the domain model requires, it buys separation between
Event-sourced Microservices
At this point, many readers begin to glaze over. “This is so much overhead, are we even buying that much value!?” Through the DDD phases, the motivating pressure has been developer productivity. But plenty of products and teams have a level of complexity that’s well handled by the team. They can move along the phases of DDD until they get to a comfortable point and stay there indefinitely. Or, indefinitely, until they hit production scaling pressures. When those requests start coming in, and SLAs show up, moving to an event-source system
Production scalability in services is unlocked by introducing event-driven communication patterns. At this level, several refactorings have happened, though each can occur in isolation.The domain model gains notions of events - operations that need to happen in other services, but are not part of the transaction boundary. That is, they can either fail with no repercussions, or can effect the wider system of services in an eventually consistent way.
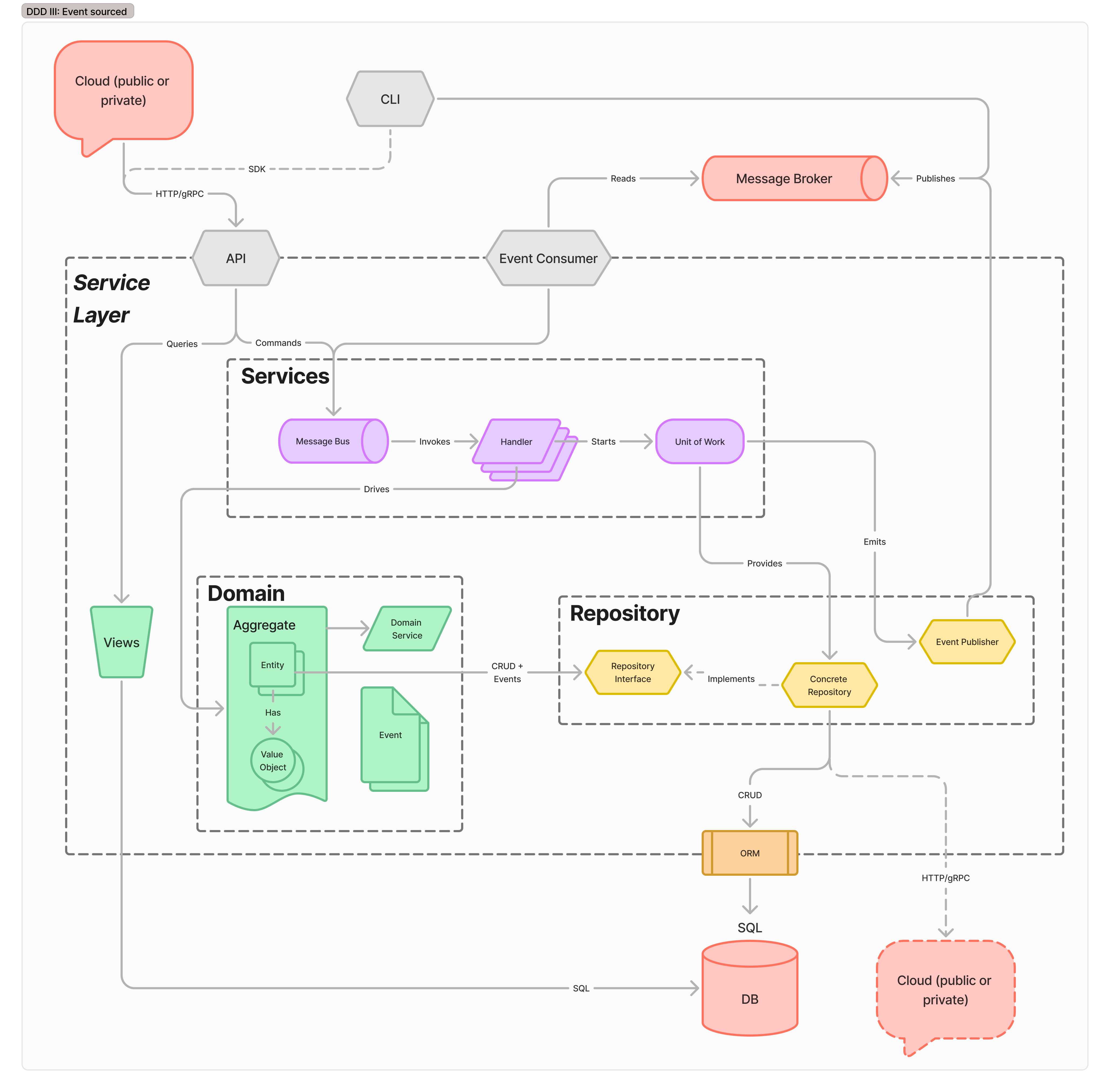
Similarly, the service may need to begin responding to events - either generated internally (as part of a secondary but separate transaction), or from outside services in the system. Instead of requiring those services to invoke this service’s API directly, a common message broker handles eventing between parts of the system.
Finally, the system may provide eventually-consistent views of its data model directly. This set of refactorings brings the service to implementing Command and Query Response Segregation. The API layer regains substantial responsibility in this mode, as it is now responsible for exposing a consistent external view to users in spite of the CQRS implementation, which may or may not be desirable to expose.This is a significant amount of complexity, but in return, buys on separate axes flexibility and responsibility. The domain model remains the only place to specify and find business logic rules. All other components have clearly specified responsibilities to safely and wrap and scale that functionality.
This system has one canonical data format, in the domain model; two schemas which can evolve in isolation for the API and DB, and several semi-constrained formats from the event consumer and downstream service APIs. Incoming requests are decoupled from the service by a message broker queue; aggregates are idempotent, and compute can scale horizontally based on queue pressure. Storage is decoupled between high-capacity write shards, and distributed to read replicas for fast simple get operations.
Summary
Start with not even an app. Get data from a Google form, put it in a spreadsheet, read from the spreadsheet into any Python program, and get the data needed for a decision.
At some point, start building a real app. This will have lifecycle, controls, things that Google Sheets doesn’t give you. Iterate on it for a while, until the domain model comes out.
Once the domain model is apparent, extract the interface for its repository. Getting to this point is, in the author’s observation, necessary for the long term health of any code base.
A further refactoring to domain aggregate and unit of work handlers can add a flourish on the architecture, but is not itself strictly necessary for most service teams.
It is necessary to move to an event-sourced architecture, which unlocks several larger systems architecture patterns. This includes queue-based event delivery & scaling, and read/write sharing + read-replica scaling.